Introduction to tidyEmoji
Youzhi
Yu
University of
Chicago
Source: vignettes/introduction.Rmd
introduction.RmdOverview
Emoji are everywhere in modern text — social-media posts, product reviews, chat and support logs, survey free-text — and they carry information that plain words do not. Yet summarising emoji from a corpus is surprisingly awkward. Unicode does not interact cleanly with regular expressions, not every code point is an emoji, and a single visible emoji is often built from several code points joined together. Counting “how many posts contain an emoji” or “which emoji are most common” by hand quickly becomes painful.
tidyEmoji removes that friction. It provides a small
family of verbs that take a data frame and the name of a text column,
and return tidy data frames that drop straight into a
dplyr/ggplot2 workflow:
| Task | Function(s) |
|---|---|
| Summarise / filter |
emoji_summary(), emoji_filter()
|
| Extract |
emoji_extract_nest(),
emoji_extract_unnest(), emoji_tokens()
|
| Count |
emoji_frequency(), top_n_emojis()
|
| Categorise | emoji_categorize() |
| Score sentiment | emoji_sentiment() |
| Score emotions |
emoji_emotion(),
emoji_emotion_label()
|
| Custom lexicons |
emoji_lexicons(),
register_emoji_lexicon(), emoji_score()
|
| Translate |
emoji_to_text(), text_to_emoji(),
as_emoji*()
|
| Search | emoji_search() |
| Relate |
emoji_pairs(), emoji_cooccurrence(),
emoji_ngrams()
|
| Measure |
emoji_position(), emoji_density(),
emoji_ratio()
|
| Model features | emoji_dfm() |
Two design choices are worth highlighting:
- Grapheme-aware detection. Detection is performed on whole grapheme clusters, so skin-tone modifiers (👍🏽) and zero-width-joiner sequences such as the family emoji (👨👩👧👦) are treated as a single emoji rather than being split into their component parts. This is illustrated in the extraction section.
-
Tidy by default. Every verb returns a tibble,
follows the
verb(data, text_column)convention, and supports unquoted column names, so the functions compose naturally with the pipe.
Example data
Throughout this vignette we use a sample of text collected in Atlanta, Georgia. The data happens to come from a social-media corpus, but nothing below is specific to any platform — any data frame with a text column will do.
ata_tweets <- readr::read_csv("ata_tweets.csv", show_col_types = FALSE)
ata_tweets
#> # A tibble: 2,000 × 1
#> full_text
#> <chr>
#> 1 "Was Justin Bieber ever at any BLM March/protest this past summer? Or ever?"
#> 2 "Whole Family gone and I’m stuck here in Brunswick 😭"
#> 3 "38 years old and I still get distracted while cleaning my room. \n\nJust in…
#> 4 "This time last year I was blasting fever nonstop by Wizkid 😭"
#> 5 "Kanye is a just a black man with a lot of confidence and y’all tear him dow…
#> 6 "Feel like being my inner self today"
#> 7 "Peep toe boots irk my sole."
#> 8 "Nah the biggest naruto fans be trying call one piece long like... nigga?"
#> 9 "if my shoes don’t arrive by next Friday imma be pissed"
#> 10 "Phone dry asf 🙄"
#> # ℹ 1,990 more rowsThe actual text lives in the full_text column, which is
the column we pass to each tidyEmoji verb.
Detecting and summarising emoji
emoji_summary()
emoji_summary() answers the first question one usually
asks of a new corpus: how much emoji is in here? It returns a
one-row tibble with the number of entries that contain at least one
emoji and the total number of entries. An entry is counted once
regardless of how many emoji it holds.
summary_tbl <- ata_tweets %>%
emoji_summary(full_text)
summary_tbl
#> # A tibble: 1 × 2
#> n_with_emoji n_total
#> <int> <int>
#> 1 560 2000Here, 560 of the 2,000 entries (28%) contain at least one emoji.
emoji_filter()
emoji_filter() keeps only the rows whose text contains
at least one emoji, preserving every original column. This is useful
when you want to compare emoji-bearing and emoji-free text, or restrict
an analysis to the emoji subset. (emoji_tweets() is a
synonym retained for backward compatibility.)
ata_tweets %>%
emoji_filter(full_text)
#> # A tibble: 560 × 1
#> full_text
#> <chr>
#> 1 Whole Family gone and I’m stuck here in Brunswick 😭
#> 2 This time last year I was blasting fever nonstop by Wizkid 😭
#> 3 Phone dry asf 🙄
#> 4 When I gave my life to Christ, I was able to see people as imperfect, but st…
#> 5 Everyone needs self care days❤️
#> 6 R u sears rn 🤦🏽♀️
#> 7 Gucci wit some dope runnas head huncho top gunna u a sto runna😭
#> 8 i’m thinking insomnia cause they got this caramel apple pie cookie. 😋
#> 9 i deadass listen to the music everyday lmao🥲
#> 10 Im ona block where ya barley can be at if you try get shot down 😈
#> # ℹ 550 more rowsExtracting emoji
tidyEmoji offers three complementary ways to pull the emoji out of text, depending on the shape of output you want.
emoji_extract_nest()
emoji_extract_nest() leaves the data unchanged except
for an added list-column, .emoji_unicode, holding the emoji
found in each row. The original data structure is preserved, which makes
this convenient as an intermediate step.
ata_tweets %>%
emoji_extract_nest(full_text) %>%
select(full_text, .emoji_unicode)
#> # A tibble: 2,000 × 2
#> full_text .emoji_unicode
#> <chr> <list>
#> 1 "Was Justin Bieber ever at any BLM March/protest this past su… <chr [0]>
#> 2 "Whole Family gone and I’m stuck here in Brunswick 😭" <chr [1]>
#> 3 "38 years old and I still get distracted while cleaning my ro… <chr [0]>
#> 4 "This time last year I was blasting fever nonstop by Wizkid 😭… <chr [1]>
#> 5 "Kanye is a just a black man with a lot of confidence and y’a… <chr [0]>
#> 6 "Feel like being my inner self today" <chr [0]>
#> 7 "Peep toe boots irk my sole." <chr [0]>
#> 8 "Nah the biggest naruto fans be trying call one piece long li… <chr [0]>
#> 9 "if my shoes don’t arrive by next Friday imma be pissed" <chr [0]>
#> 10 "Phone dry asf 🙄" <chr [1]>
#> # ℹ 1,990 more rows
emoji_extract_unnest()
emoji_extract_unnest() returns a long, tidy table with
one row per (entry, emoji) pair: .row_number records the
position of the entry in the data, .emoji_unicode is the
emoji, and .emoji_count is how many times that emoji occurs
in that entry. Entries without emoji are dropped.
emoji_per_tweet <- ata_tweets %>%
emoji_extract_unnest(full_text)
emoji_per_tweet
#> # A tibble: 697 × 3
#> .row_number .emoji_unicode .emoji_count
#> <int> <chr> <int>
#> 1 2 😭 1
#> 2 4 😭 1
#> 3 10 🙄 1
#> 4 15 😂 1
#> 5 17 ❤️ 1
#> 6 30 🤦🏽♀️ 1
#> 7 31 😭 1
#> 8 33 😋 1
#> 9 42 🥲 1
#> 10 45 😈 1
#> # ℹ 687 more rowsWe can use this to plot how many emoji each emoji-bearing entry contains:
emoji_per_tweet %>%
group_by(.row_number) %>%
summarise(n_emoji = sum(.emoji_count)) %>%
ggplot(aes(n_emoji)) +
geom_bar() +
scale_x_continuous(breaks = seq(1, 15)) +
labs(x = "Number of emoji in the entry",
y = "Number of entries",
title = "Most emoji-bearing entries contain a single emoji")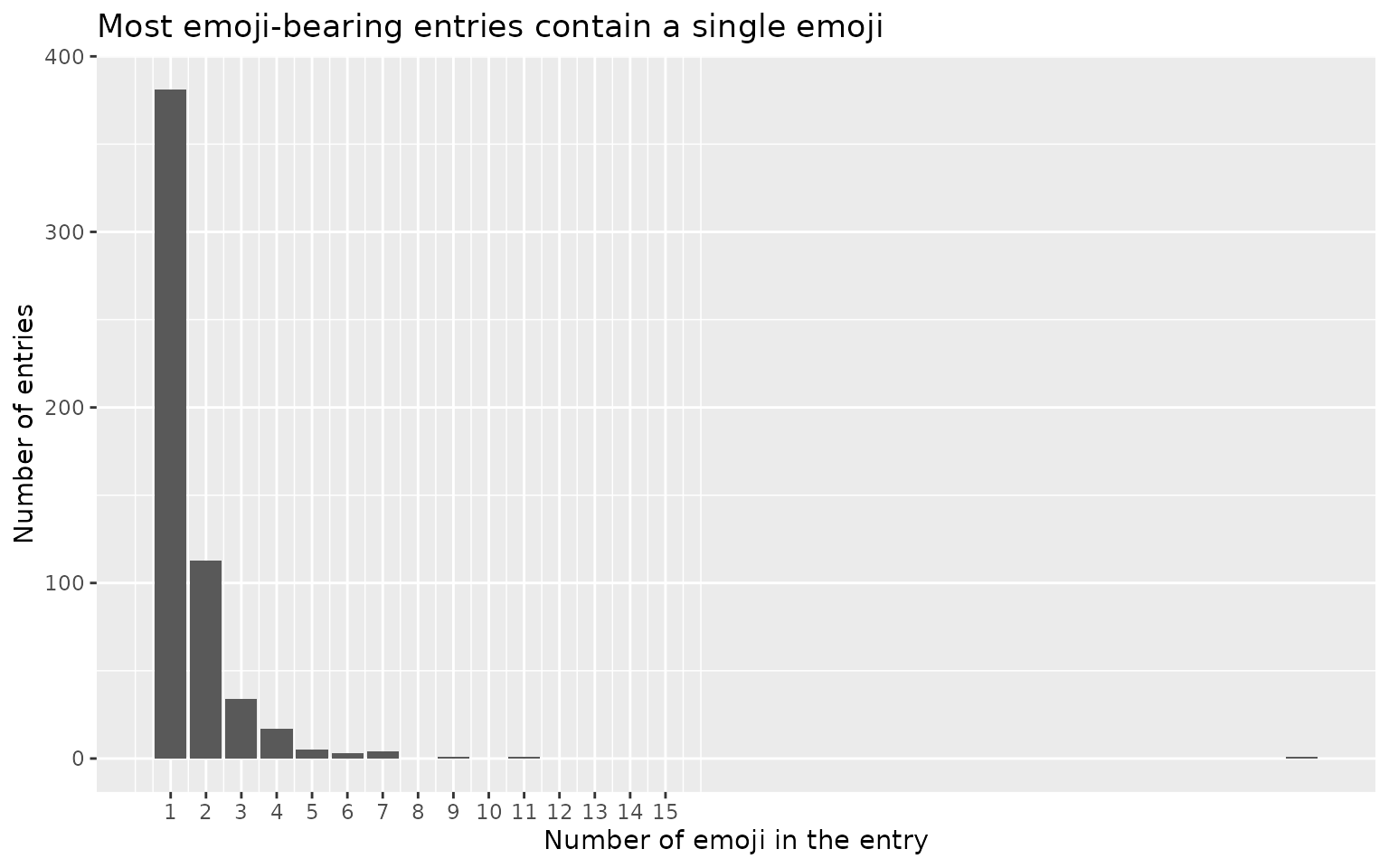
The overwhelming majority of emoji-bearing entries carry just one emoji, with a long, thin tail of more emoji-heavy entries.
emoji_tokens()
emoji_tokens() produces a “one row per emoji occurrence”
table — the emoji analogue of a tidy-text token table. It keeps the
original columns and adds the glyph (.emoji) together with
its name (.emoji_name), category
(.emoji_category) and sentiment score
(.emoji_sentiment). This single call gives you everything
needed for counting, joining and plotting.
ata_tweets %>%
emoji_tokens(full_text)
#> # A tibble: 901 × 5
#> full_text .emoji .emoji_name .emoji_category .emoji_sentiment
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 Whole Family gone and I’… 😭 loudly cry… Smileys & Emot… -0.0934
#> 2 This time last year I wa… 😭 loudly cry… Smileys & Emot… -0.0934
#> 3 Phone dry asf 🙄 🙄 face with … Smileys & Emot… NA
#> 4 When I gave my life to C… 😂 face with … Smileys & Emot… 0.221
#> 5 Everyone needs self care… ❤️ red heart Smileys & Emot… 0.746
#> 6 R u sears rn 🤦🏽♀️ 🤦🏽♀️ woman face… People & Body NA
#> 7 Gucci wit some dope runn… 😭 loudly cry… Smileys & Emot… -0.0934
#> 8 i’m thinking insomnia ca… 😋 face savor… Smileys & Emot… 0.634
#> 9 i deadass listen to the … 🥲 smiling fa… Smileys & Emot… NA
#> 10 Im ona block where ya ba… 😈 smiling fa… Smileys & Emot… 0.268
#> # ℹ 891 more rowsA note on grapheme-aware detection
Modern emoji are frequently composed of several code points: a base emoji plus a skin-tone modifier, or several emoji joined by zero-width joiners. tidyEmoji detects emoji at the level of grapheme clusters, so these stay intact. The example below contains exactly two emoji — one family and one thumbs-up — and tidyEmoji counts them as such rather than splitting the family into four people or separating the thumb from its skin tone:
demo <- data.frame(
text = c("our family \U0001F468\U0001F469\U0001F467\U0001F466",
"great work \U0001F44D\U0001F3FD")
)
demo %>%
emoji_extract_unnest(text)
#> # A tibble: 2 × 3
#> .row_number .emoji_unicode .emoji_count
#> <int> <chr> <int>
#> 1 1 👨👩👧👦 1
#> 2 2 👍🏽 1Counting emoji across the corpus
emoji_frequency()
emoji_frequency() counts how often each emoji appears
across the whole text column (an entry containing the same emoji twice
contributes 2) and returns the result sorted by descending count,
annotated with each emoji’s name, shortcode and category.
ata_tweets %>%
emoji_frequency(full_text)
#> # A tibble: 188 × 5
#> emoji name shortcode group n
#> <chr> <chr> <chr> <chr> <int>
#> 1 😂 face with tears of joy joy Smil… 160
#> 2 😭 loudly crying face sob Smil… 98
#> 3 😩 weary face weary Smil… 34
#> 4 🤣 rolling on the floor laughing rofl Smil… 34
#> 5 🥺 pleading face pleading_face Smil… 29
#> 6 🙄 face with rolling eyes roll_eyes Smil… 22
#> 7 🥴 woozy face woozy_face Smil… 21
#> 8 💯 hundred points 100 Smil… 20
#> 9 😍 smiling face with heart-eyes heart_eyes Smil… 20
#> 10 🥰 smiling face with hearts smiling_face_with_three_hear… Smil… 20
#> # ℹ 178 more rows
top_n_emojis()
When you only need the leaders, top_n_emojis() is a
convenience wrapper around emoji_frequency() that returns
the n most frequent emoji (default
n = 20).
top_20_emojis <- ata_tweets %>%
top_n_emojis(full_text)
top_20_emojis
#> # A tibble: 20 × 4
#> emoji_name unicode emoji_category n
#> <chr> <chr> <chr> <int>
#> 1 joy 😂 Smileys & Emotion 160
#> 2 sob 😭 Smileys & Emotion 98
#> 3 weary 😩 Smileys & Emotion 34
#> 4 rofl 🤣 Smileys & Emotion 34
#> 5 pleading_face 🥺 Smileys & Emotion 29
#> 6 roll_eyes 🙄 Smileys & Emotion 22
#> 7 woozy_face 🥴 Smileys & Emotion 21
#> 8 100 💯 Smileys & Emotion 20
#> 9 heart_eyes 😍 Smileys & Emotion 20
#> 10 smiling_face_with_three_hearts 🥰 Smileys & Emotion 20
#> 11 bangbang ‼️ Symbols 14
#> 12 folded_hands_medium_dark_skin_tone 🙏🏾 People & Body 12
#> 13 heart ❤️ Smileys & Emotion 11
#> 14 skull 💀 Smileys & Emotion 10
#> 15 unamused 😒 Smileys & Emotion 10
#> 16 rage 😡 Smileys & Emotion 10
#> 17 sparkles ✨ Activities 9
#> 18 eyes 👀 People & Body 9
#> 19 relieved 😌 Smileys & Emotion 9
#> 20 raising_hands_medium_dark_skin_tone 🙌🏾 People & Body 9Plotting the top 20, coloured by category, gives an immediate sense of how the community expresses itself:
top_20_emojis %>%
mutate(emoji_name = stringr::str_replace_all(emoji_name, "_", " "),
emoji_name = forcats::fct_reorder(emoji_name, n)) %>%
ggplot(aes(n, emoji_name, fill = emoji_category)) +
geom_col() +
labs(x = "Count",
y = NULL,
fill = "Category",
title = "The 20 most frequent emoji")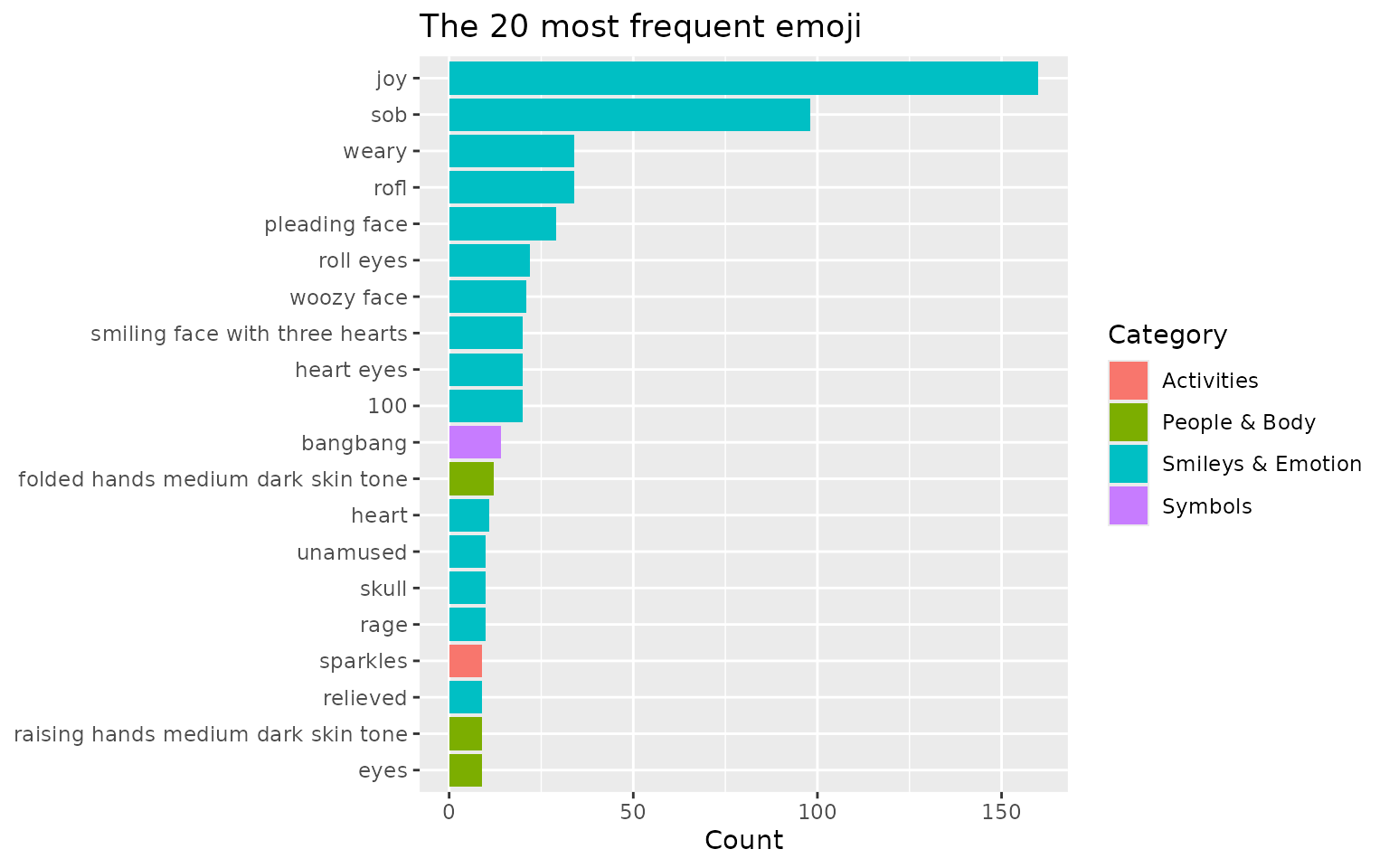
The unicode column holds the actual glyph, should you
wish to render the emoji themselves on a plot (this requires a graphics
device with an emoji-capable font). You can also request a different
number of emoji:
ata_tweets %>%
top_n_emojis(full_text, n = 10) %>%
mutate(emoji_name = stringr::str_replace_all(emoji_name, "_", " "),
emoji_name = forcats::fct_reorder(emoji_name, n)) %>%
ggplot(aes(n, emoji_name, fill = emoji_category)) +
geom_col() +
labs(x = "Count", y = NULL, fill = "Category",
title = "The 10 most frequent emoji")
Categorising emoji
The Unicode standard organises emoji into 10 categories (see
?category_unicode_crosswalk).
emoji_categorize() keeps the emoji-bearing rows and adds a
.emoji_category column listing the distinct categories
present in each row, separated by | when a row spans more
than one.
ata_emoji_category <- ata_tweets %>%
emoji_categorize(full_text) %>%
select(.emoji_category)
ata_emoji_category
#> # A tibble: 560 × 1
#> .emoji_category
#> <chr>
#> 1 Smileys & Emotion
#> 2 Smileys & Emotion
#> 3 Smileys & Emotion
#> 4 Smileys & Emotion
#> 5 Smileys & Emotion
#> 6 People & Body
#> 7 Smileys & Emotion
#> 8 Smileys & Emotion
#> 9 Smileys & Emotion
#> 10 Smileys & Emotion
#> # ℹ 550 more rowsWe can tally the most common category combinations:
ata_emoji_category %>%
count(.emoji_category, sort = TRUE) %>%
filter(n > 20) %>%
mutate(.emoji_category = forcats::fct_reorder(.emoji_category, n)) %>%
ggplot(aes(n, .emoji_category)) +
geom_col() +
labs(x = "Number of entries", y = NULL,
title = "Most common emoji category combinations")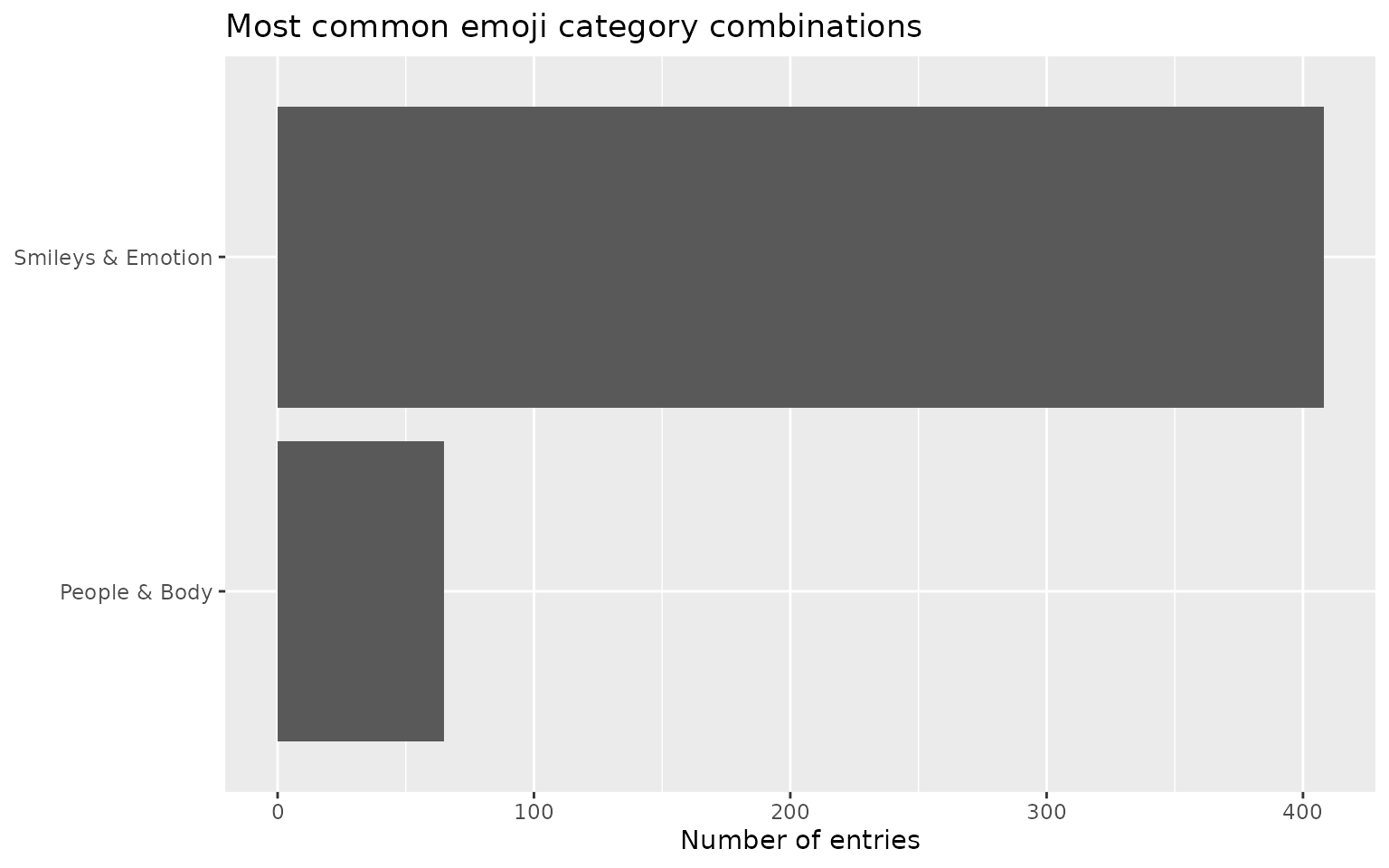
To count the 10 individual categories rather than their combinations,
split the .emoji_category strings on | with
tidyr::separate_rows():
ata_emoji_category %>%
tidyr::separate_rows(.emoji_category, sep = "\\|") %>%
count(.emoji_category, sort = TRUE) %>%
mutate(.emoji_category = forcats::fct_reorder(.emoji_category, n)) %>%
ggplot(aes(n, .emoji_category)) +
geom_col() +
labs(x = "Number of entries", y = NULL,
title = "Emoji category usage")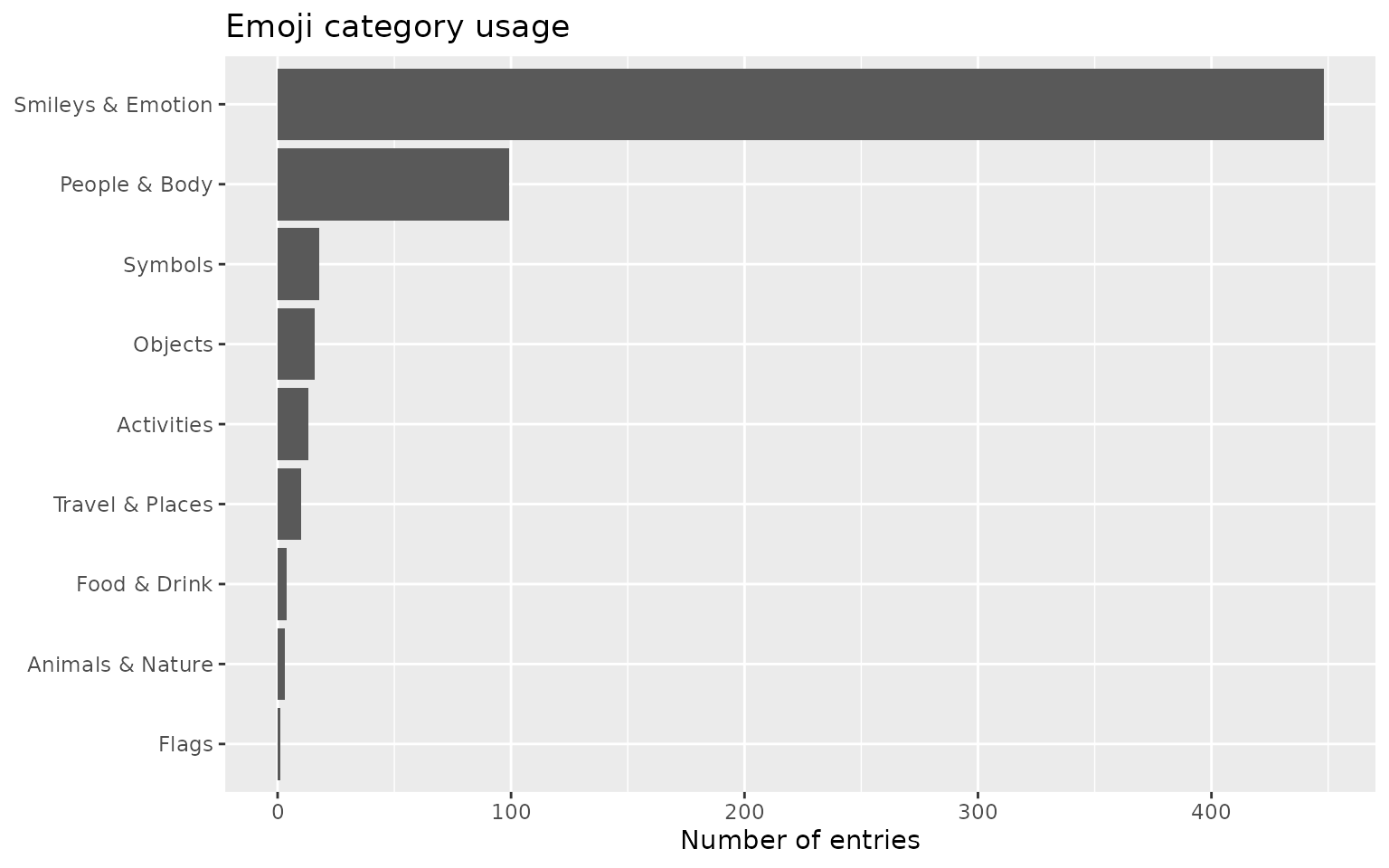
“Smileys & Emotion” dominates, followed by “People & Body”. Note that an entry spanning several categories is counted once in each, so these counts can exceed the number of emoji-bearing entries.
Scoring emoji sentiment
emoji_sentiment()
Emoji are a strong sentiment signal, and
emoji_sentiment() surfaces it directly. It adds
.emoji_n (the number of emoji in the entry),
.emoji_n_scored (the number that appear in the lexicon),
and .emoji_sentiment (the mean sentiment of the scored
emoji, from -1 to +1). Scores come from the bundled
emoji_sentiment_lexicon (described below); entries with no
emoji, or whose emoji are not in the lexicon, receive
NA.
ata_sentiment <- ata_tweets %>%
emoji_sentiment(full_text)
ata_sentiment %>%
select(.emoji_n, .emoji_sentiment)
#> # A tibble: 2,000 × 2
#> .emoji_n .emoji_sentiment
#> <int> <dbl>
#> 1 0 NA
#> 2 1 -0.0934
#> 3 0 NA
#> 4 1 -0.0934
#> 5 0 NA
#> 6 0 NA
#> 7 0 NA
#> 8 0 NA
#> 9 0 NA
#> 10 1 NA
#> # ℹ 1,990 more rowsSentiment distribution
Looking across the entries that contain at least one scored emoji:
ata_sentiment %>%
filter(!is.na(.emoji_sentiment)) %>%
ggplot(aes(.emoji_sentiment)) +
geom_histogram(binwidth = 0.1) +
labs(x = "Mean emoji sentiment",
y = "Number of entries",
title = "Emoji sentiment skews positive")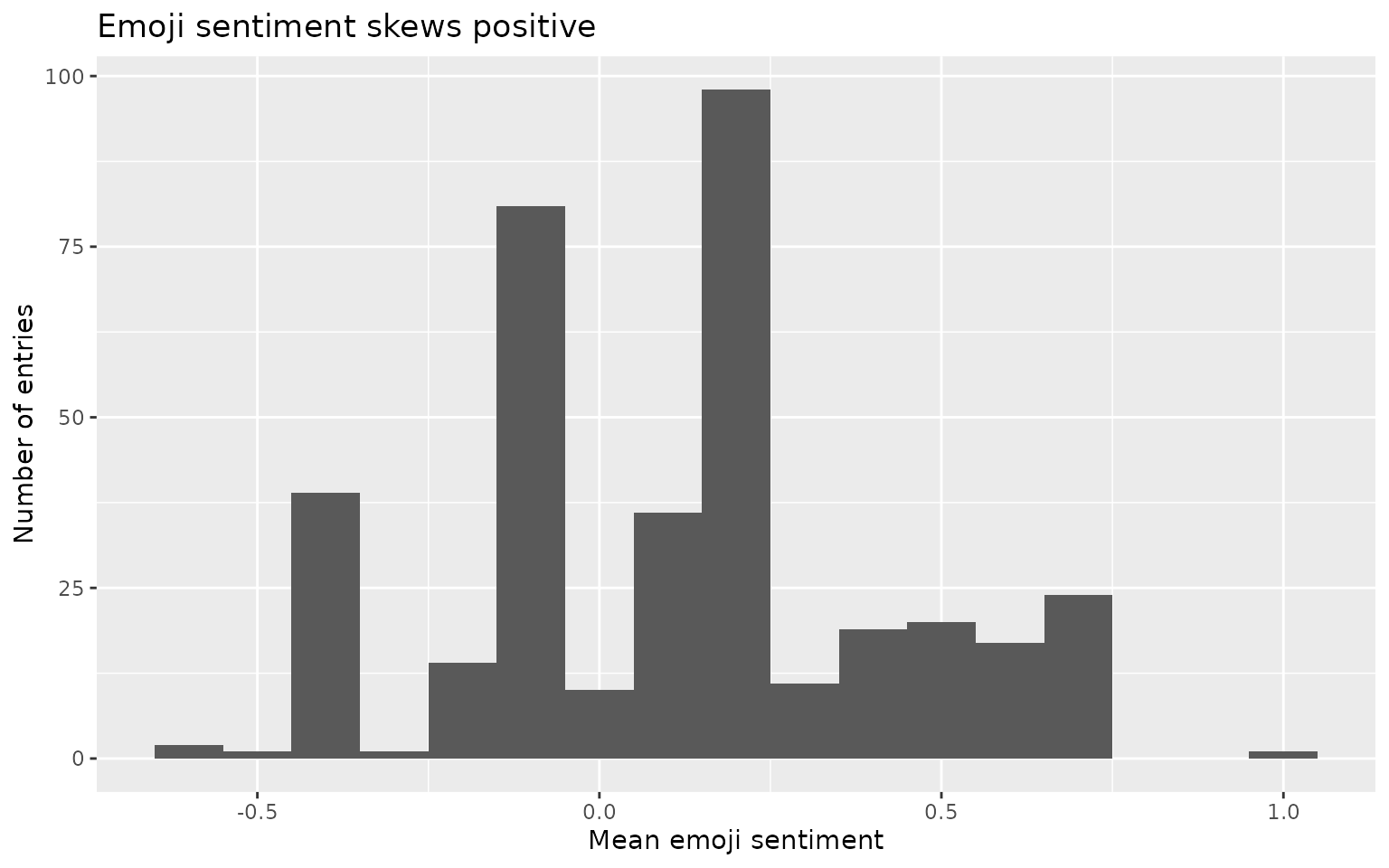
As is typical of social-media text, emoji sentiment leans strongly positive.
Sentiment by category
Because emoji_tokens() attaches a sentiment score to
every emoji occurrence, we can summarise average sentiment by category
in a couple of lines:
ata_tweets %>%
emoji_tokens(full_text) %>%
group_by(.emoji_category) %>%
summarise(mean_sentiment = mean(.emoji_sentiment, na.rm = TRUE),
n_scored = sum(!is.na(.emoji_sentiment))) %>%
filter(n_scored > 0) %>%
mutate(.emoji_category = forcats::fct_reorder(.emoji_category, mean_sentiment)) %>%
ggplot(aes(mean_sentiment, .emoji_category)) +
geom_col() +
labs(x = "Mean sentiment", y = NULL,
title = "Average emoji sentiment by category")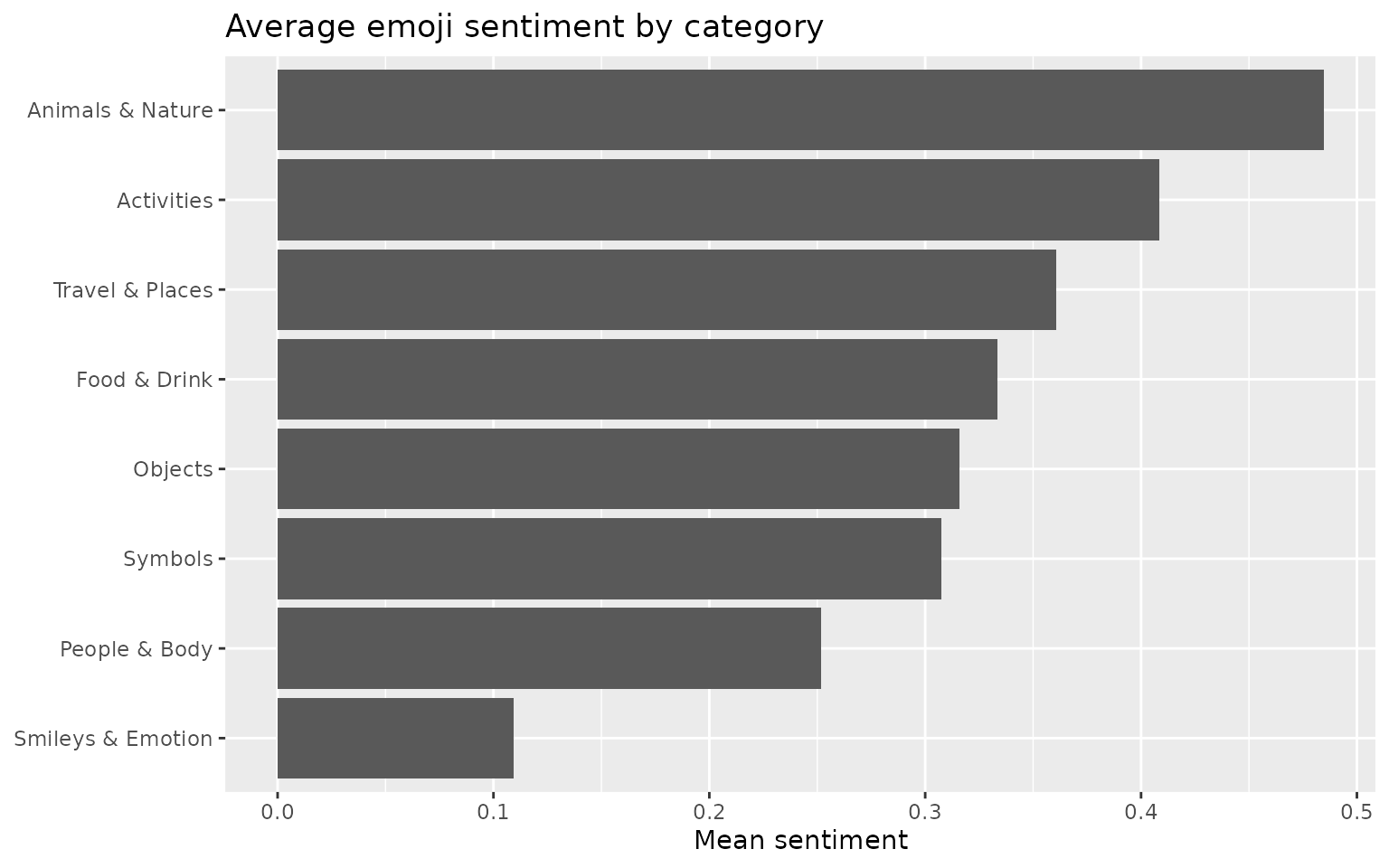
The sentiment lexicon
The scores come from emoji_sentiment_lexicon, the
Emoji Sentiment Ranking of Kralj Novak et al. (2015), computed
from around 70,000 tweets annotated in 13 European languages. You can
work with it directly — for instance, to find the most positive and most
negative reasonably common emoji:
emoji_sentiment_lexicon %>%
filter(occurrences >= 500) %>%
slice_max(sentiment_score, n = 8) %>%
select(emoji, unicode_name, occurrences, sentiment_score)
#> emoji unicode_name occurrences sentiment_score
#> 1 ❤ HEAVY BLACK HEART 8050 0.7460870
#> 2 💞 REVOLVING HEARTS 687 0.7423581
#> 3 🎉 PARTY POPPER 1125 0.7395556
#> 4 💃 DANCER 1344 0.7358631
#> 5 💙 BLUE HEART 912 0.7324561
#> 6 💖 SPARKLING HEART 1263 0.7133808
#> 7 💛 YELLOW HEART 602 0.7126246
#> 8 😘 FACE THROWING A KISS 3648 0.7017544
emoji_sentiment_lexicon %>%
filter(occurrences >= 500) %>%
slice_min(sentiment_score, n = 8) %>%
select(emoji, unicode_name, occurrences, sentiment_score)
#> emoji unicode_name occurrences sentiment_score
#> 1 😒 UNAMUSED FACE 1385 -0.37472924
#> 2 😩 WEARY FACE 1808 -0.36836283
#> 3 🔫 PISTOL 604 -0.19536424
#> 4 😡 POUTING FACE 756 -0.17328042
#> 5 😔 PENSIVE FACE 1205 -0.14605809
#> 6 😞 DISAPPOINTED FACE 532 -0.11842105
#> 7 😭 LOUDLY CRYING FACE 5526 -0.09337676
#> 8 😴 SLEEPING FACE 718 -0.08077994Scoring emoji emotions
Valence (negative↔︎positive) is only one affective dimension.
emoji_emotion() goes further, scoring each entry’s emoji
across the eight Plutchik emotions (anger, anticipation, disgust, fear,
joy, sadness, surprise, trust) using the bundled EmoTag1200 lexicon
(Shoeb & de Melo, 2020). Scores are in [0, 1].
ata_emotion <- ata_tweets %>%
emoji_emotion(full_text)
ata_emotion %>%
select(.emoji_joy, .emoji_trust, .emoji_anger, .emoji_n)
#> # A tibble: 2,000 × 4
#> .emoji_joy .emoji_trust .emoji_anger .emoji_n
#> <dbl> <dbl> <dbl> <int>
#> 1 NA NA NA 0
#> 2 0 0.08 0.22 1
#> 3 NA NA NA 0
#> 4 0 0.08 0.22 1
#> 5 NA NA NA 0
#> 6 NA NA NA 0
#> 7 NA NA NA 0
#> 8 NA NA NA 0
#> 9 NA NA NA 0
#> 10 NA NA NA 1
#> # ℹ 1,990 more rowsA quick way to read the result is the dominant emotion per entry:
ata_tweets %>%
emoji_emotion_label(full_text) %>%
count(.emoji_emotion, sort = TRUE)
#> # A tibble: 9 × 2
#> .emoji_emotion n
#> <chr> <int>
#> 1 NA 1639
#> 2 joy 166
#> 3 sadness 115
#> 4 anticipation 30
#> 5 surprise 15
#> 6 anger 12
#> 7 disgust 11
#> 8 fear 10
#> 9 trust 2The emotion scores join through the same codepoint-normalised key as
sentiment, so emoji carrying the U+FE0F variation selector
resolve correctly.
Bringing your own lexicon
Sentiment and emotion scoring share one pluggable engine.
emoji_lexicons() lists the bundled lexicons (plus any you
have registered):
emoji_lexicons()
#> # A tibble: 2 × 6
#> name type dimensions n source licence
#> <chr> <chr> <I<list>> <int> <chr> <chr>
#> 1 novak2015 sentiment <chr [1]> 969 Kralj Novak et al. (2015), PLoS… CC BY-…
#> 2 emotag1200 emotion <chr [8]> 150 Shoeb & de Melo (2020), EMNLP 2… MITemoji_score() is the generic scorer underneath
emoji_sentiment(): give it any data frame with an emoji
column and a score column — say, scores tailored to your own domain —
and it returns the per-row mean, joined through the same
codepoint-normalised key as everything else:
my_lexicon <- data.frame(
emoji = c("\U0001f600", "\U0001f621", "\U0001f637"),
score = c(1, -1, -0.5)
)
data.frame(text = c("great \U0001f600", "bad \U0001f621\U0001f637", "none")) %>%
emoji_score(text, lexicon = my_lexicon)
#> # A tibble: 3 × 4
#> text .emoji_score .emoji_n_scored .emoji_n
#> <chr> <dbl> <int> <int>
#> 1 great 😀 1 1 1
#> 2 bad 😡😷 -0.75 2 2
#> 3 none NA NA 0register_emoji_lexicon() stores a lexicon under a name
for the session, so you can refer to it in emoji_score() —
or in emoji_emotion(), if it carries emotion columns:
register_emoji_lexicon("mine", my_lexicon)
emoji_lexicons() %>% filter(name == "mine")
#> # A tibble: 1 × 6
#> name type dimensions n source licence
#> <chr> <chr> <I<list>> <int> <chr> <chr>
#> 1 mine custom <chr [1]> 3 user-registered NARelating emoji: co-occurrence and sequences
Which emoji appear together? emoji_pairs()
returns a tidy edge list — one row per pair of distinct emoji that
co-occur in the same entry, with the number of entries in which they do.
The item1/item2/n shape matches
widyr::pairwise_count() and feeds directly into graph tools
such as igraph, tidygraph and ggraph:
emoji_edges <- ata_tweets %>%
emoji_pairs(full_text)
emoji_edges
#> # A tibble: 214 × 3
#> item1 item2 n
#> <chr> <chr> <int>
#> 1 😂 😭 10
#> 2 😂 😩 4
#> 3 😂 🙄 3
#> 4 😭 🙄 3
#> 5 💕 🥰 2
#> 6 💞 🥺 2
#> 7 💯 🤷🏽♂️ 2
#> 8 🤔 😂 2
#> 9 🤣 😂 2
#> 10 🤷🏼♀️ 😂 2
#> # ℹ 204 more rowsThe strongest pairings make a readable chart on their own:
emoji_edges %>%
slice_max(n, n = 10) %>%
mutate(pair = paste(item1, item2),
pair = forcats::fct_reorder(pair, n)) %>%
ggplot(aes(n, pair)) +
geom_col() +
labs(x = "Number of entries containing both", y = NULL,
title = "Emoji that appear together")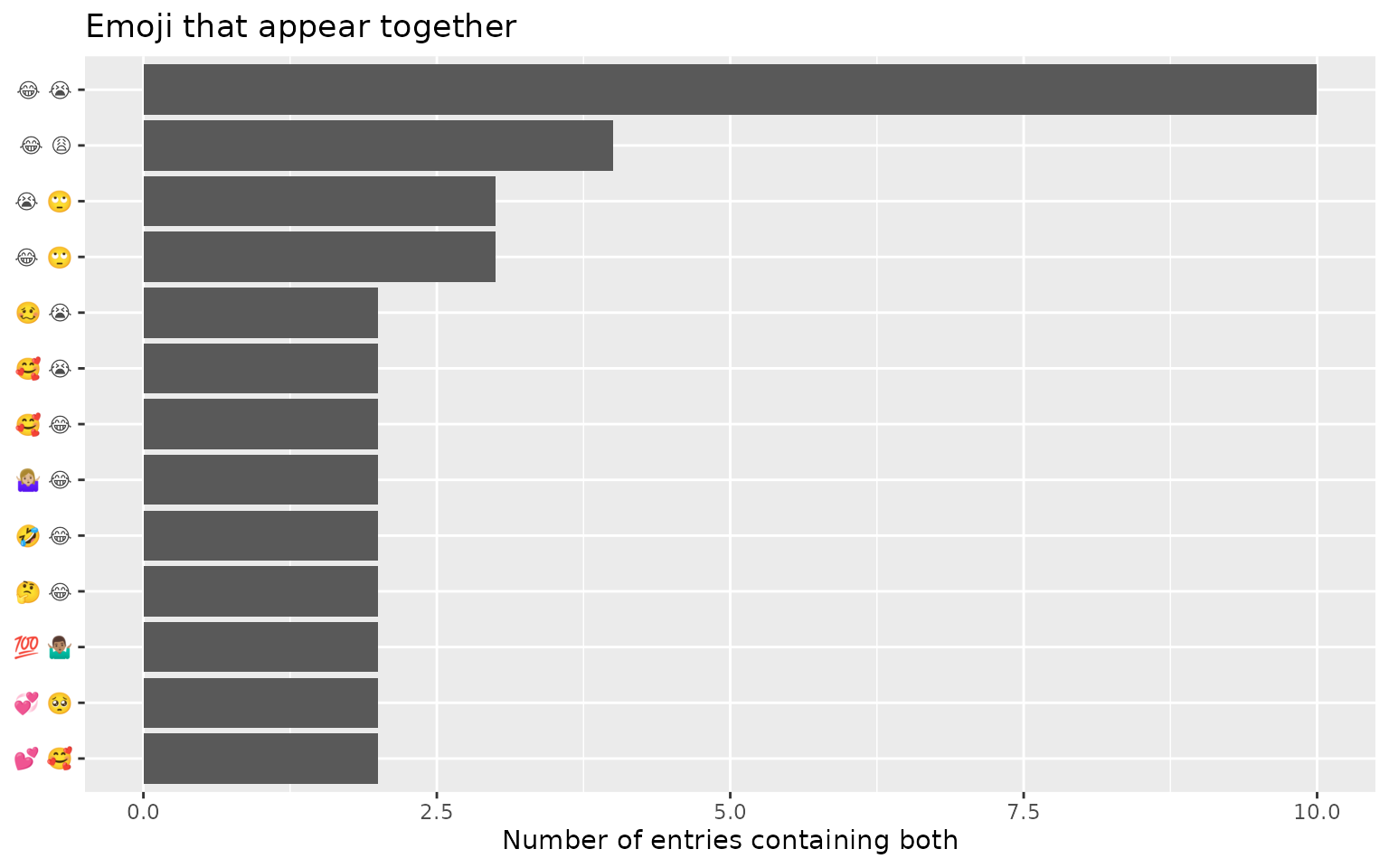
Set directed = TRUE to order each pair by first
appearance, or supply doc_id to pool several rows (a
conversation, a user, a day) into one document.
emoji_cooccurrence(diagonal = TRUE) additionally returns
each emoji’s document frequency on the diagonal.
Order also matters within an entry.
emoji_ngrams() slides a window over each entry’s emoji in
reading order (any text in between is ignored), which is the raw
material for sequence and Markov-style analyses:
ata_tweets %>%
emoji_ngrams(full_text) %>%
count(.emoji_ngram, sort = TRUE)
#> # A tibble: 159 × 2
#> .emoji_ngram n
#> <chr> <int>
#> 1 😂 😂 66
#> 2 😭 😭 27
#> 3 😍 😍 13
#> 4 🥺 🥺 13
#> 5 🤣 🤣 10
#> 6 😭 😂 8
#> 7 🖕🏻 🖕🏻 7
#> 8 😡 😡 5
#> 9 🙏🏾 🙏🏾 5
#> 10 💀 💀 4
#> # ℹ 149 more rowsAll the relational verbs canonicalise glyphs through the same codepoint-normalised key as the rest of the package, so qualified and unqualified forms of one emoji count as a single node.
Measuring how emoji are used
Where emoji sit and how much of the text they
occupy are studied signals in their own right.
emoji_position() reports each entry’s first and last emoji
position and the mean relative position from 0 (start) to 1 (end):
ata_tweets %>%
emoji_position(full_text) %>%
filter(!is.na(.emoji_rel_position)) %>%
ggplot(aes(.emoji_rel_position)) +
geom_histogram(binwidth = 0.05) +
labs(x = "Mean relative position of the entry's emoji",
y = "Number of entries",
title = "Emoji cluster at the end of a message")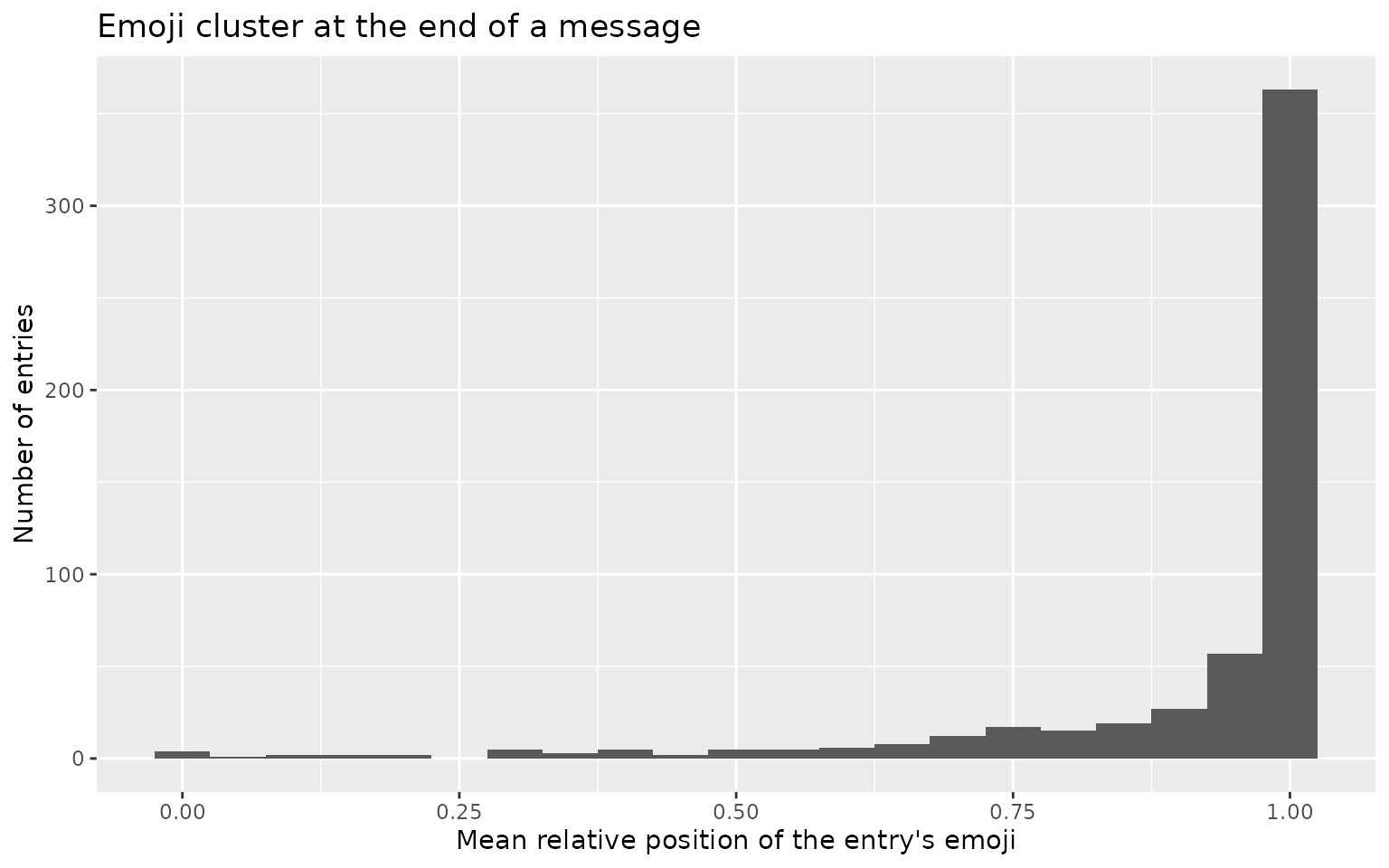
emoji_density() normalises the emoji count by text
length (per character and per whitespace-delimited token), and
emoji_ratio() reports what share of the text’s characters
belong to emoji — including an .emoji_only flag for entries
that are nothing but emoji (and whitespace):
Emoji as model features
For classification and regression work, emoji_dfm()
turns the corpus into a document-by-emoji feature table: one row per
entry (or per doc_id), one column per emoji, weighted by
counts, binary presence or tf-idf. Every entry is kept — emoji-free rows
are all zeros — so the table binds row-for-row to your outcome
columns:
ata_tweets %>%
emoji_dfm(full_text, weighting = "tfidf") %>%
select(1:6)
#> # A tibble: 2,000 × 6
#> .row_number `😂` `😭` `🤣` `😩` `🥺`
#> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 1 0 0 0 0 0
#> 2 2 0 3.34 0 0 0
#> 3 3 0 0 0 0 0
#> 4 4 0 3.34 0 0 0
#> 5 5 0 0 0 0 0
#> 6 6 0 0 0 0 0
#> 7 7 0 0 0 0 0
#> 8 8 0 0 0 0 0
#> 9 9 0 0 0 0 0
#> 10 10 0 0 0 0 0
#> # ℹ 1,990 more rowsTranslating emoji to and from text
Replacing emoji with words is useful for accessibility (screen
readers) and as an NLP normalisation step before tokenising.
emoji_to_text() does this for a whole column, in either
Unicode-name or shortcode form; text_to_emoji() is the
inverse.
demo <- data.frame(text = "great \U0001f600 love \u2764\ufe0f")
demo %>% emoji_to_text(text, format = "name")
#> # A tibble: 1 × 1
#> text
#> <chr>
#> 1 great grinning face love red heart
demo %>% emoji_to_text(text, format = "shortcode")
#> # A tibble: 1 × 1
#> text
#> <chr>
#> 1 great :grinning: love :heart:
demo %>%
emoji_to_text(text, format = "shortcode") %>%
text_to_emoji(text)
#> # A tibble: 1 × 1
#> text
#> <chr>
#> 1 great 😀 love ❤️Note that the qualified heart (which carries the U+FE0F
variation selector) translates just as reliably as any other emoji,
thanks to the normalised join key. For ad-hoc, vector-level use there
are also as_emoji_name(), as_emoji_shortcode()
and as_emoji():
as_emoji_name(c("\U0001f600", "\u2764\ufe0f"))
#> [1] "grinning face" "red heart"
as_emoji_shortcode(c("\U0001f600", "\u2764\ufe0f"))
#> [1] "grinning" "heart"
as_emoji(c("grinning", "heart"))
#> [1] "😀" "❤️"Searching the emoji catalogue
emoji_search() looks emoji up by keyword, name or
shortcode (case-insensitive, literal matching), returning a tidy tibble
you can filter further or feed into the other verbs:
emoji_search("happy")
#> # A tibble: 27 × 5
#> emoji name shortcode group keyword
#> <chr> <chr> <chr> <chr> <chr>
#> 1 😀 grinning face grinning Smileys … happy
#> 2 😃 grinning face with big eyes smiley Smileys … happy
#> 3 😄 grinning face with smiling eyes smile Smileys … happy
#> 4 😁 beaming face with smiling eyes grin Smileys … happy
#> 5 😆 grinning squinting face laughing Smileys … happy
#> 6 🤣 rolling on the floor laughing rofl Smileys … happy
#> 7 😂 face with tears of joy joy Smileys … happy
#> 8 🙂 slightly smiling face slightly_smiling_face Smileys … happy
#> 9 😇 smiling face with halo innocent Smileys … happy
#> 10 ☺ smiling face smiling_face Smileys … happy
#> # ℹ 17 more rows
emoji_search("celebration")
#> # A tibble: 27 × 5
#> emoji name shortcode group keyword
#> <chr> <chr> <chr> <chr> <chr>
#> 1 🥳 partying face partying_face Smileys & Emotion celebration
#> 2 🙌 raising hands raised_hands People & Body celebration
#> 3 🎅 Santa Claus santa People & Body celebration
#> 4 🤶 Mrs. Claus mrs_claus People & Body celebration
#> 5 🧑🎄 Mx Claus mx_claus People & Body celebration
#> 6 🎂 birthday cake birthday Food & Drink celebration
#> 7 🍾 bottle with popping cork champagne Food & Drink celebration
#> 8 🎃 jack-o-lantern jack_o_lantern Activities celebration
#> 9 🎄 Christmas tree christmas_tree Activities celebration
#> 10 🎆 fireworks fireworks Activities celebration
#> # ℹ 17 more rowsBundled datasets
tidyEmoji ships four datasets, each documented with its own help page:
-
emoji_sentiment_lexicon— emoji sentiment scores from the Emoji Sentiment Ranking (see?emoji_sentiment_lexicon). -
emoji_emotion_lexicon— emoji emotion scores from EmoTag1200 (see?emoji_emotion_lexicon). -
emoji_unicode_crosswalk— one row per emoji name, mapping names / shortcodes to glyphs and categories. -
category_unicode_crosswalk— one row per Unicode category, listing its emoji.
These are regenerated from the current Unicode emoji list by the
scripts in the package’s data-raw/ directory.
References
Kralj Novak P, Smailović J, Sluban B, Mozetič I (2015). Sentiment of Emojis. PLoS ONE 10(12): e0144296. https://doi.org/10.1371/journal.pone.0144296. The Emoji Sentiment Ranking is distributed under the Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0) licence.
Shoeb AAM, de Melo G (2020). EmoTag1200: Understanding the Association between Emojis and Emotions. EMNLP 2020. https://aclanthology.org/2020.emnlp-main.720/. The EmoTag1200 data is distributed under the MIT licence.